#32632 closed Bug (fixed)
Query resolution can be at least 3x slower in 3.2
| Reported by: | Phillip Cutter | Owned by: | Simon Charette |
|---|---|---|---|
| Component: | Database layer (models, ORM) | Version: | 3.2 |
| Severity: | Release blocker | Keywords: | |
| Cc: | Simon Charette, Oskar Persson | Triage Stage: | Ready for checkin |
| Has patch: | yes | Needs documentation: | no |
| Needs tests: | no | Patch needs improvement: | no |
| Easy pickings: | no | UI/UX: | no |
Description
I recently upgraded to Django 3.2 from 3.1.8 and found running my queries were taking nearly 15 seconds to run compared to a few milliseconds in 3.1.8. To help bring this issue to light I've created a basic Django project on GitHub with a test case that shows this issue. Running "manage.py test" on Django 3.2 and Django 3.1.8 shows that 3.2 is taking roughly 3x as long to build the query, while not executing the query.
Repository with test case: https://github.com/mrfleap/django-db-test
The underlying query is admittedly repetitive, but I still feel it this degradation in performance should not go overlooked. Through some basic debugging I believe the issue may lie django/utils/tree.py on line 93 (https://github.com/django/django/blob/stable/3.2.x/django/utils/tree.py#L93) where it checks to see if a node is within a list of children, one of my basic tests found the operation to take 9 seconds alone, rather than the fractions of a millisecond it usually takes. I've attached a screenshot of my breakpoint to showcase that it's taking ~9 seconds to determine if one node exists in an array of two.
I'd also like to point out that I am using Django Guardian quite heavily in this scenario, which is leading to the complicated query in the first place. However, as far as I am aware, there is no difference in the generated query between both versions, and the difference in speed is based on how Django is resolving the internal objects into a SQL statement.
Please let me know if there's any other information I can provide to help fix this issue.
Attachments (1)
{kind=link}
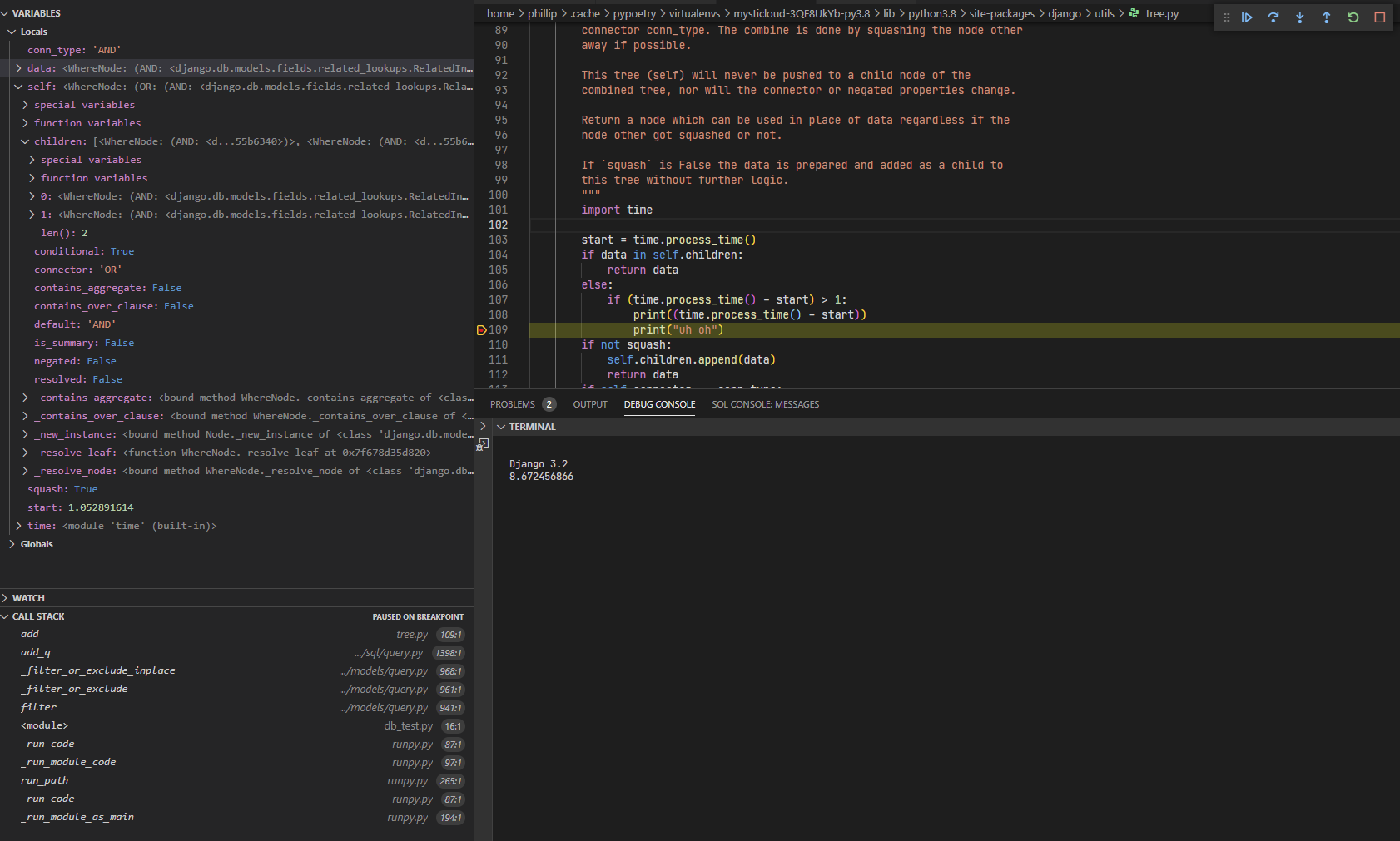{kind=link}
Change History (11)
by , 4 years ago
| Attachment: | slow_tree_resolution.png added |
|---|
comment:1 by , 4 years ago
| Cc: | added |
|---|---|
| Severity: | Normal → Release blocker |
| Triage Stage: | Unreviewed → Accepted |
Thanks for the report. Tentatively accepted, I'm not sure if it's feasible to improve a performance and keep the fix for #32143.
Performance regression in bbf141bcdc31f1324048af9233583a523ac54c94.
Reproduced at 1351f2ee163145df2cf5471eb3e57289f8853512.
comment:2 by , 4 years ago
| Owner: | changed from to |
|---|---|
| Status: | new → assigned |
comment:3 by , 4 years ago
| Cc: | added |
|---|
comment:4 by , 4 years ago
Alright so I did a bit of digging in the past hour and here are my findings
Before bbf141bcdc31f1324048af9233583a523ac54c94 Query.__eq__ was wrongly returning True due to making it a subclass BaseExpression in 35431298226165986ad07e91f9d3aca721ff38ec. Before these changes Query.__eq__ was not implemented which meant that Model.objects.filter(foo=bar).query != Model.objects.filter(foo=bar).query as object.__eq__ is based of id(self) == id(other). This is problematic for expressions such as Exists and Subquery which are based off sql.Query and need to be able to compare to each other to implement the expression API.
Since sql.Query is an immutable internal object we could possibly cached_property(identity) and move along as that cuts the slowdown in about half, that does feel like a bandaid solution though. It's interesting to me that Node.add would compare all its children in the first place as that seems like a costly operation with little benefit in the first place.
After playing around with a few things here's a list of two proposed solutions
- Remove the
tree.Node.addbranch forif data in self.children. While it's covered by the suite only a single test in the whole suite reaches the branch under arguably convoluted conditions while the check is performed 99% of the time whenfilterandexcludeare called to perform expensive O(n) operations. I wouldn't be surprised if it was at the origin of others recent slowdowns in the ORM query construction due to the introduction ofBaseExpression.identitydue to needs for deconstruc-ability imposed byIndex(condition)andConstraint(condition). - Make
Subquery(andExists) explicitly non-deconstructible; in practice they already are becausesql.Querydoesn't properly implementdeconstructso there's little value in implementingidentityfor them in the first place. - Remove the
sql.Query(BaseExpression)subclassing as it's no longer necessary in practice. That'll have the side effect of removing support forModel.objects.filter(foo=bar).query == Model.objects.filter(foo=bar).querywhich is a nice property but since we don't internally have a need for it yet there's little point in the complexity it incurs.
I'd suggest we backport 2. and 3. to address this ticket and move the discussion about 1. in a new Cleanup/optimization one. Let me know if that makes sense to you and I'll commit to a PR before the end of April.
comment:5 by , 4 years ago
Thanks for the investigation!
2 & 3 make sense for me, however I would like to see an implementation first. This can be too massive for backporting. I'm a bit afraid that we can open the Pandora's box.
Will we be able to keep support for combining Q() objects with boolean expressions?
comment:6 by , 4 years ago
| Has patch: | set |
|---|
2 & 3 make sense for me, however I would like to see an implementation first. This can be too massive for backporting. I'm a bit afraid that we can open the Pandora's box.
Hopefully the proposed patch is not too invasive, I could try to figure out another approach. From an invasivity reduction perspective removing the Node.add branch seems like a clear choice for this particular issue but I wouldn't be surprised if other code paths were affected by the slowness introduced by sql.Query.__eq__.
Will we be able to keep support for combining Q() objects with boolean expressions?
Yep, it shouldn't be an issue. The main change is really that Subquery doesn't partially implement the deconstruct API which is only really useful for migrations anyway.
comment:7 by , 4 years ago
| Triage Stage: | Accepted → Ready for checkin |
|---|
Screenshot showing breakpoint set during query building in a separate repository