#5423 closed New feature (fixed)
"dumpdata" should stream output one row at a time
| Reported by: | Adrian Holovaty | Owned by: | Ramiro Morales |
|---|---|---|---|
| Component: | Core (Serialization) | Version: | dev |
| Severity: | Normal | Keywords: | dumpdata fixtures memory |
| Cc: | Jason McVetta, Torsten Bronger, kmike84@…, Tom Christie, bgneal@…, riccardo.magliocchetti@…, pelletier.thomas@…, znick, ben@…, dpmcgee@…, jann@…, hakon.erichsen@…, Chris Spencer, mmitar@…, wgordonw1@… | Triage Stage: | Ready for checkin |
| Has patch: | yes | Needs documentation: | no |
| Needs tests: | no | Patch needs improvement: | no |
| Easy pickings: | no | UI/UX: | no |
Description
I attempted to run django-admin.py dumpdata on a database table with ~2,000 records, and it ran out of memory. This problem would be avoided if dumpdata output its dump one line at a time, like an iterator does.
Attachments (13)
{kind=link}
{kind=link}
Change History (75)
comment:1 by , 17 years ago
| Triage Stage: | Unreviewed → Accepted |
|---|
comment:2 by , 17 years ago
comment:3 by , 17 years ago
During django sprint... tested before and after the patch and noticed no effect. The dump consumed about 100M of my free memory while it was churning, then dumped everything to screen and the 100M became free again.
comment:4 by , 17 years ago
After a bit more testing, I've discovered:
- Using the default JSON format stream doesn't appear to stream -- it churns until all rows are in memory and then it dumps to stdout. (The XML serializer contrasts this by dumping to stdout immediately.)
- Using --format=xml the stream option does in fact stream to stdout, but in the end it still consumes the same amount of memory. Perhaps there's a bug in that memory isn't being freed as it iterates?
comment:5 by , 17 years ago
| Has patch: | set |
|---|
Here is a patch that streams json data per object. It also uses a generator method for the object list instead of storing everything in a list beforehand. This should get rid of your memory problems (you are welcome to test this patch).
Note that yaml output has the same streaming problem which is not fixed here.
comment:7 by , 17 years ago
| Patch needs improvement: | set |
|---|
comment:8 by , 17 years ago
I used this patch and changed model.objects.all() to model.objects.iterator() in django/core/management/commands/dumpdata.py. After that I was successfully able to dump a considerably big database (1Gb SQLite file). Python process resident memory size was at about 20M all the time.
comment:9 by , 17 years ago
Thanks Densetsu. Looks pretty good from a quick skim over - someone else from this ticket want to review the patch and report back?
comment:10 by , 17 years ago
| Patch needs improvement: | unset |
|---|
The .iterator() thing was the missing piece, nice work. I am adding a cleaned up patch that does not have the date formatting changes from my local repository.
by , 17 years ago
| Attachment: | django_dumpdata_streamed_output_2.diff added |
|---|
Cleanup up revision, using objects.iterator()
comment:11 by , 17 years ago
I have applied the latest patch 'django_dumpdata_streamed_output_2.diff' from 10/20/07, on the latest version from svn.
I have a huge database (> 300,000 entries - sqlite db)
The error is: "Error: Unable to serialize database: 'NoneType' object has no attribute 'strftime'"
by , 17 years ago
| Attachment: | django_dumpdata_streamed_output_3.diff added |
|---|
Newest version, fixing modeltests
comment:12 by , 16 years ago
Even with django_dumpdata_streamed_output_3.diff, i still go OOM trying to dump tables with 250k rows in them to json.
comment:13 by , 16 years ago
Apologies to everyone: i'm an idiot. It does stream and doesn't eat memory, django_dumpdata_streamed_output_3.diff works fine with 250k objects... I had DEBUG=True.
by , 16 years ago
| Attachment: | dumpdata_streamed_output_django1.0.diff added |
|---|
fixed patch to work with django 1.0
comment:14 by , 16 years ago
This patch has bugs:
- Ordering models by model._meta.pk.attname fails on models where primary key is OneToOneField ('parent' vs 'parent_id').
- JSON separator is not placed between model entries, due to first=True inside loop The attached patch corrects them.
comment:15 by , 16 years ago
I mean dumpdata_streamed_output_django1.0-fix.diff fixes the bugs mentioned above and there are no more bugs known to me :)
comment:16 by , 16 years ago
I installed the patch, but still have to watch django eat up all the memory without any output, when I try to dump my database (>700.000 records) :(
Debug is False. Is there anything else where I could go wrong? What's the format with the least memory use?
comment:17 by , 16 years ago
| Cc: | added |
|---|---|
| Keywords: | dumpdata loaddata fixtures memory added |
It appears the latest patch has already been applied to trunk:
$ patch -p1 < ~/incoming/dumpdata_streamed_output_django1.0-fix.diff patching file django/core/management/commands/dumpdata.py Reversed (or previously applied) patch detected! Assume -R? [n]
I experienced no problems using dumpdata to export a ~160,000 record fixture, in both json and yaml formats. However, while I was able run loaddata on the json fixture without incident, attempting to load the yaml fixture quickly overwhelmed the memory on my 4GB workstation.
comment:18 by , 16 years ago
@jmcvetta I don't think this has yet been added to trunk. Just checked today, 7 Apr 2009.
Glad to hear that you got it working with your patch but I don't think I can use that patch any more on the trunk since it appears to be very different.
comment:19 by , 15 years ago
The problem is not in dumpdata, it's in the Django Serialisation code. The core.serializers.python.Serializer doesn't start writing to the output stream until all objects to be serialised have been read into memory.
The attached patches won't work until the above is addressed.
comment:21 by , 15 years ago
Dumpdata is a light wrapper around the serializers. Any problem with dumpdata that goes deeper than command arguments not being parsed correctly points to a deeper issue with the serialiers themselves.
comment:22 by , 15 years ago
| Component: | django-admin.py → Serialization |
|---|---|
| Patch needs improvement: | set |
OK, then we're agreed this is a Serializer issue.
One approach would be to have the format Serializers handle the "list of objects" logic manually. E.g. for JSON, have start_serialization write "to the stream; have end_object write a comma to stream if needed and dump the object tree to stream using simplejson; end_serialization needs to write the"; the existing objects member should be removed all together. I might have a bash at a patch this weekend.
comment:23 by , 15 years ago
Oops. Should have used preview. That should read:
One approach would be to have the format Serializers handle the "list of objects" logic manually. E.g. for JSON, have start_serialization write open-square-bracket to the stream; have end_object write a comma to stream if needed and dump the object tree to stream using simplejson; end_serialization needs to write the close-square-bracket; the existing objects member should be removed all together.
I might have a bash at a patch this weekend.
comment:25 by , 15 years ago
#10301 marked as a duplicate. It has a patch that could be an alternative solution.
comment:26 by , 14 years ago
| Cc: | added |
|---|
comment:27 by , 14 years ago
| Owner: | changed from to |
|---|---|
| Status: | new → assigned |
comment:28 by , 14 years ago
| Patch needs improvement: | unset |
|---|
comment:29 by , 14 years ago
| Keywords: | loaddata removed |
|---|
Removing loaddata keyword. Loaddata has its own ticket tracking memory its usage issues (#12007).
Please test the latest patch and report back your experiences. I have created a test environment to measure, graph and compare memory usage: https://bitbucket.org/cramm/serializers_memory_usage/src
by , 14 years ago
| Attachment: | 5423.2.diff added |
|---|
Another update, with fixes to JSON output so it is always syntactically correct.
by , 14 years ago
| Attachment: | json-postgresq-trunk.png added |
|---|
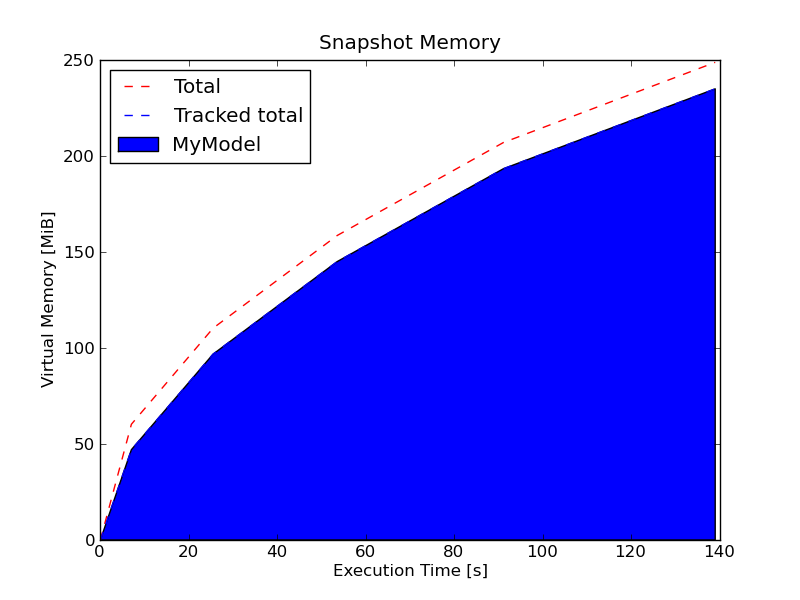
Memory usage with dumpdata of 50,000 objects, Postgres, JSON format, unpatched trunk
by , 14 years ago
| Attachment: | json-postgresq-trunk-patched.png added |
|---|
Memory usage with dumpdata of same 50,000 objects, Postgres, JSON format, trunk patched with 5423.2.diff
comment:30 by , 14 years ago
Results obtained testing with the setup described at and downloadable from https://bitbucket.org/cramm/serializers_memory_usage/src (serialization of 50,000 instances of this model to JSON). Results with XML, YAMS and MySQL, SQLite3 are similar.
Unpatched trunk

Patched trunk

follow-up: 32 comment:31 by , 14 years ago
I try dumpdata with latest patch
python manage.py dumpdata -a > dump.json
at the end of work from top:
446m 429m 3460 R 96.4 12.3 2:54.07 python manage.py dumpdata -a
ls -lha dump.json
-rw-r--r-- 1 boris boris 77M Мар 10 17:50 dump.json
I din't think that it is ok.
Also, dumpdata doesn't flush data on disk while working
data flush only at the end
comment:32 by , 14 years ago
Replying to Boris Savelev <boris.savelev@…>:
Thanks for testing the patch. I've reformatted your comment so it is more readable. Can you tell us which database backend are you using?
comment:34 by , 14 years ago
| Cc: | added |
|---|
comment:35 by , 14 years ago
| Cc: | added |
|---|
comment:36 by , 14 years ago
| Severity: | → Normal |
|---|---|
| Type: | → New feature |
comment:37 by , 14 years ago
| Cc: | added |
|---|
comment:38 by , 14 years ago
| Cc: | added |
|---|---|
| Easy pickings: | unset |
comment:39 by , 13 years ago
| Triage Stage: | Accepted → Ready for checkin |
|---|---|
| UI/UX: | unset |
follow-up: 45 comment:40 by , 13 years ago
| Patch needs improvement: | set |
|---|---|
| Triage Stage: | Ready for checkin → Accepted |
Unfortunately the patch isn't ready, some comments and further testing showed that in the PostgreSQL case big ORM queries are still consuming too mucho memory.
I suspect the patch solves things in the Django side because it implements usage of QuerySet.iterator(). But we still need to add to e.g. our PostgreSQL backend the ability to signal psycopg2/RDBMS it shouldn't get all the queryset from the server, maybe using server-side cursors.
comment:41 by , 13 years ago
(above comment was from me)
Some links that might prove useful for anybody wishing to attack this:
comment:42 by , 13 years ago
| Cc: | added |
|---|
comment:43 by , 13 years ago
| Cc: | added |
|---|
comment:44 by , 13 years ago
| Cc: | added |
|---|
comment:45 by , 13 years ago
Replying to ramiro:
Unfortunately the patch isn't ready, some comments and further testing showed that in the PostgreSQL case big ORM queries are still consuming too mucho memory.
I suspect the patch solves things in the Django side because it implemenst usage of QuerySet.iterator(). But we still need to add to e.g. outr PostgreSQL backend the ability to signal psycopg2/RDBMS it shouldn't get all the queryset from the server, maybe using server-side cursors.
I'm going to respectfully disagree with your switch away from "Ready for checkin".
- This patch still improves the situation heavily, as it eliminates the double caching problems that existed in both database drivers and the Django querysets.
- Looking into server side cursors, I was going to attempt to implement this, but it turns out the Django ORM is built with a fundamental limitation- that you have one connection with one cursor to a given database, period. Take a look at
django/db/backends/__init__.py, you will see the cursor() method always returns the single cached cursor object from the BaseDatabaseWrapper object. This works if every query is fully executed and the cursor is available for immediate reuse, but with any sort of iteration, you can't touch the shared cursor object and would need to create a new one solely for that purpose. This brings with it a whole new bag of worms- now you have to encapsulate the cursor and close it when done, among other things, which is a non-trivial addition to the current database code.
So in short, I think holding off on applying this is the wrong decision, and another bug should be opened, related to #13869 and this one, that adds full support for server side cursors and the management of them, or their equivalent, in every database backend. Then it should be a simple 1 or 2 line adjustment to make dumpdata take advantage of this new feature.
comment:46 by , 13 years ago
My last comment looks like it isn't totally correct- Django does give you a new cursor each time you ask for one. Apparently we never close cursors? Not sure if this is a potential problem in some DBMSs.
With that said, I still stand by my view that server-side cursors is fundamentally a different problem and should not hold this patch from going in.
comment:47 by , 13 years ago
New ticket opened with preliminary patch for server-side cursors: #16614.
comment:48 by , 13 years ago
| Cc: | added |
|---|
comment:49 by , 13 years ago
When using patch 5423.1.diff, 5423.2.diff or 5423.3.diff, we're still saving all the data in a StreamIO object instead of writing it directly to sys.stdout, which caused huge memory usage again...
I combined 5423.diff and 5423.3.diff which solved the problem for me.
comment:50 by , 13 years ago
| Cc: | added |
|---|
follow-up: 52 comment:51 by , 13 years ago
Just tried new patch with mysql. For me it's still consumes about 250 megs. But it's way more better than "out of memory".
311m 257m 4040 R 79 25.8 4:36.47 python
236M 2011-10-02 11:28 dump.json
comment:52 by , 13 years ago
Ah, I forgot to post my memory usage ... I have about 50 models with about 3.5m rows in total...
It results in a 2.2G json file and peaks at about 173m of used memory during the process.
We're using PostgreSQL by the way.
Replying to pzinovkin:
Just tried new patch with mysql. For me it's still consumes about 250 megs. But it's way more better than "out of memory".
311m 257m 4040 R 79 25.8 4:36.47 python236M 2011-10-02 11:28 dump.json
comment:53 by , 13 years ago
| Cc: | added |
|---|
comment:54 by , 13 years ago
| Cc: | added |
|---|
comment:55 by , 13 years ago
| Cc: | added |
|---|
comment:56 by , 13 years ago
Attempted to update for trunk - will one of the original authors please check this, and then mark it Ready-For-Checkin and I will commit.
I confirm that this helps a lot - one dumpdata process I tried with went from max 247MB to max 77MB.
I agree with toofishes that we should not wait for the much bigger changes that would be required to address the further caching problems with the DB drivers.
comment:57 by , 13 years ago
| Cc: | added |
|---|
comment:58 by , 13 years ago
As promised on IRC to cramm (xrmx here) here's some results with / without latest lukeplant's patch on top of django 1.4b1.
First my environment is a bit peculiar, i have a fixed limit of address space (the sum of all kind of memory) a process can use, in this case 96MB. So if my process consume more than 96MB it gets killed.
Before patch:
../venv14/bin/python manage.py dumpdata store > store.json /venv14/lib/python2.6/site-packages/django/conf/__init__.py:75: DeprecationWarning: The ADMIN_MEDIA_PREFIX setting has been removed; use STATIC_URL instead. "use STATIC_URL instead.", DeprecationWarning) Error: Unable to serialize database:
process got killed so no backtrace printed, store.json is empty
After patch:
../venv14/bin/python manage.py dumpdata store > store.json /venv14/lib/python2.6/site-packages/django/conf/__init__.py:75: DeprecationWarning: The ADMIN_MEDIA_PREFIX setting has been removed; use STATIC_URL instead. "use STATIC_URL instead.", DeprecationWarning)
$ ls -l store.json 17496440 2012-03-05 10:02 store.json
To conclude the patch makes a huge difference in my environment, from not working to working.
comment:59 by , 13 years ago
| Patch needs improvement: | unset |
|---|---|
| Triage Stage: | Accepted → Ready for checkin |
The patch looks good to me. I tried running it against a database that use to exhaust all memory and never achieved to actually finish dumping the data and it succeed.
comment:60 by , 13 years ago
| Resolution: | → fixed |
|---|---|
| Status: | assigned → closed |
follow-up: 62 comment:61 by , 12 years ago
With these changes, serialized objects now seem to start with "[ ,", which is wrong (including a comma, even on the first result.)
This patch allows me to export my data sets correctly, but does so with an invalid JSON schema, and does not allow me to import them.
comment:62 by , 12 years ago
Replying to barry.melton@…:
With these changes, serialized objects now seem to start with "[ ,", which is wrong (including a comma, even on the first result.)
Looking at the test cases, I don't think your assertion is True. However, it is possible your use case is not covered by test cases. So please provide us more details so as we can try to reproduce the faulty JSON result.
Just as a point of reference, I dumped a table with 100k+ rows into YAML without problems... so there's obviously a situation-dependant quality to this one.